Search Engine LITE
This website uses the following detailed custom search engine. Please use the search option to test this functionality. How to create you own search engine. In order to create you own search engine you need to have the following components.1. A web crawler or spider module.
2. A parser for gleaning the words in the page content eg. getWordsCount() (given below)
3. A database to store the page links and words and their count. The database schema can be of 2 tables.
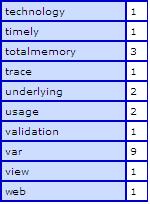
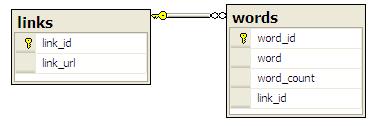 The getWordsCount() function (given below) will return a structure
containing all distinct words and their repetition count within the
spidered page. All you need to do is update the database tables with
the information received and your search data is now ready.
With the data ready, now you can provide an interface to query this
database and display the results.
The getWordsCount() function (given below) will return a structure
containing all distinct words and their repetition count within the
spidered page. All you need to do is update the database tables with
the information received and your search data is now ready.
With the data ready, now you can provide an interface to query this
database and display the results.
Search Engine Lite code
<!---
<cfdump var="#getWordsCount('http://ketanjetty.com/monitor/jvm-runtime/')#" />
--->
<cffunction name="getWordsCount" access="public" returntype="struct">
<cfargument name="_page" type="string" required="true" />
<cfset var page = arguments._page />
<cfset var tempWord = "" />
<cfset var i = 0 />
<cfset var wordsCountStruct = StructNew() />
<cfset var wordsToAvoidJSON = '{ "able":"", "about":"", "above":"", "abroad":"", "according":"", "accordingly":"", "across":"", "actually":"", "adj":"", "after":"", "afterwards":"", "again":"", "against":"", "ago":"", "ahead":"", "ain''t":"", "all":"", "allow":"", "allows":"", "almost":"", "alone":"", "along":"", "alongside":"", "already":"", "also":"", "although":"", "always":"", "am":"", "amid":"", "amidst":"", "among":"", "amongst":"", "an":"", "and":"", "another":"", "any":"", "anybody":"", "anyhow":"", "anyone":"", "anything":"", "anyway":"", "anyways":"", "anywhere":"", "apart":"", "appear":"", "appreciate":"", "appropriate":"", "are":"", "aren''t":"", "around":"", "as":"", "a''s":"", "aside":"", "ask":"", "asking":"", "associated":"", "at":"", "available":"", "away":"", "awfully":"", "back":"", "backward":"", "backwards":"", "be":"", "became":"", "because":"", "become":"", "becomes":"", "becoming":"", "been":"", "before":"", "beforehand":"", "begin":"", "behind":"", "being":"", "believe":"", "below":"", "beside":"", "besides":"", "best":"", "better":"", "between":"", "beyond":"", "both":"", "brief":"", "but":"", "by":"", "came":"", "can":"", "cannot":"", "cant":"", "can''t":"", "caption":"", "cause":"", "causes":"", "certain":"", "certainly":"", "changes":"", "clearly":"", "c''mon":"", "co":"", "co.":"", "com":"", "come":"", "comes":"", "completely":"", "concerning":"", "consequently":"", "consider":"", "considering":"", "contain":"", "containing":"", "contains":"", "corresponding":"", "could":"", "couldn''t":"", "course":"", "c''s":"", "currently":"", "dare":"", "daren''t":"", "decrease":"", "decreasingly":"", "definitely":"", "described":"", "despite":"", "did":"", "didn''t":"", "different":"", "directly":"", "do":"", "does":"", "doesn''t":"", "doing":"", "done":"", "don''t":"", "down":"", "downwards":"", "during":"", "each":"", "eg":"", "eight":"", "eighty":"", "either":"", "else":"", "elsewhere":"", "end":"", "ending":"", "enough":"", "entirely":"", "especially":"", "et":"", "etc":"", "even":"", "ever":"", "evermore":"", "every":"", "everybody":"", "everyone":"", "everything":"", "everywhere":"", "ex":"", "exactly":"", "example":"", "except":"", "fairly":"", "false":"", "far":"", "farther":"", "few":"", "fewer":"", "fifth":"", "first":"", "firstly":"", "five":"", "followed":"", "following":"", "follows":"", "for":"", "forever":"", "former":"", "formerly":"", "forth":"", "forward":"", "found":"", "four":"", "from":"", "further":"", "furthermore":"", "get":"", "gets":"", "getting":"", "given":"", "gives":"", "go":"", "goes":"", "going":"", "gone":"", "got":"", "gotten":"", "greetings":"", "had":"", "hadn''t":"", "half":"", "happens":"", "hardly":"", "has":"", "hasn''t":"", "have":"", "haven''t":"", "having":"", "he":"", "he''d":"", "he''ll":"", "hello":"", "help":"", "hence":"", "her":"", "here":"", "hereafter":"", "hereby":"", "herein":"", "here''s":"", "hereupon":"", "hers":"", "herself":"", "he''s":"", "hi":"", "him":"", "himself":"", "his":"", "hither":"", "hopefully":"", "how":"", "howbeit":"", "however":"", "hundred":"", "i":"", "i''d":"", "ie":"", "if":"", "ignored":"", "i''ll":"", "i''m":"", "immediate":"", "in":"", "inasmuch":"", "inc":"", "increase":"", "increasingly":"", "indeed":"", "indicate":"", "indicated":"", "indicates":"", "inner":"", "inside":"", "insofar":"", "instead":"", "into":"", "inward":"", "is":"", "isn''t":"", "it":"", "it''d":"", "it''ll":"", "its":"", "it''s":"", "itself":"", "i''ve":"", "just":"", "keep":"", "keeps":"", "kept":"", "know":"", "known":"", "knows":"", "last":"", "lastly":"", "lately":"", "later":"", "latter":"", "latterly":"", "least":"", "less":"", "lest":"", "let":"", "let''s":"", "like":"", "liked":"", "likely":"", "likewise":"", "little":"", "look":"", "looking":"", "looks":"", "low":"", "lower":"", "ltd":"", "made":"", "main":"", "mainly":"", "make":"", "makes":"", "many":"", "may":"", "maybe":"", "mayn''t":"", "me":"", "mean":"", "meantime":"", "meanwhile":"", "merely":"", "might":"", "mightn''t":"", "mine":"", "minus":"", "miss":"", "more":"", "moreover":"", "most":"", "mostly":"", "mr":"", "mrs":"", "ms":"", "much":"", "must":"", "mustn''t":"", "my":"", "myself":"", "name":"", "namely":"", "nd":"", "near":"", "nearly":"", "necessary":"", "need":"", "needn''t":"", "needs":"", "neither":"", "never":"", "never":"", "neverless":"", "nevertheless":"", "new":"", "next":"", "nine":"", "ninety":"", "no":"", "nobody":"", "non":"", "none":"", "nonetheless":"", "noone":"", "no-one":"", "nor":"", "normally":"", "not":"", "nothing":"", "notwithstanding":"", "novel":"", "now":"", "nowhere":"", "obviously":"", "of":"", "off":"", "often":"", "oh":"", "ok":"", "okay":"", "old":"", "on":"", "once":"", "one":"", "ones":"", "one''s":"", "only":"", "onto":"", "opposite":"", "or":"", "other":"", "others":"", "otherwise":"", "ought":"", "oughtn''t":"", "our":"", "ours":"", "ourselves":"", "out":"", "outside":"", "over":"", "overall":"", "own":"", "particular":"", "particularly":"", "past":"", "per":"", "perfectly":"", "perhaps":"", "placed":"", "please":"", "plus":"", "possible":"", "presumably":"", "probably":"", "provided":"", "provides":"", "que":"", "quick":"", "quickly":"", "quite":"", "qv":"", "rather":"", "rd":"", "re":"", "really":"", "reasonably":"", "recent":"", "recently":"", "regarding":"", "regardless":"", "regards":"", "relatively":"", "respectively":"", "right":"", "round":"", "said":"", "same":"", "saw":"", "say":"", "saying":"", "says":"", "second":"", "secondly":"", "see":"", "seeing":"", "seem":"", "seemed":"", "seeming":"", "seems":"", "seen":"", "self":"", "selves":"", "sensible":"", "sent":"", "serious":"", "seriously":"", "seven":"", "several":"", "shall":"", "shan''t":"", "she":"", "she''d":"", "she''ll":"", "she''s":"", "should":"", "shouldn''t":"", "since":"", "six":"", "so":"", "some":"", "somebody":"", "someday":"", "somehow":"", "someone":"", "something":"", "sometime":"", "sometimes":"", "somewhat":"", "somewhere":"", "soon":"", "sorry":"", "specified":"", "specify":"", "specifying":"", "still":"", "sub":"", "such":"", "sup":"", "sure":"", "surely":"", "take":"", "taken":"", "taking":"", "tell":"", "tends":"", "th":"", "than":"", "thank":"", "thanks":"", "thanx":"", "that":"", "that''ll":"", "thats":"", "that''s":"", "that''ve":"", "the":"", "their":"", "theirs":"", "them":"", "themselves":"", "then":"", "thence":"", "there":"", "thereafter":"", "thereby":"", "there''d":"", "therefore":"", "therein":"", "there''ll":"", "there''re":"", "theres":"", "there''s":"", "thereupon":"", "there''ve":"", "these":"", "they":"", "they''d":"", "they''ll":"", "they''re":"", "they''ve":"", "thing":"", "things":"", "think":"", "third":"", "thirty":"", "this":"", "thorough":"", "thoroughly":"", "those":"", "though":"", "three":"", "thrice":"", "through":"", "throughout":"", "thru":"", "thus":"", "thusly":"", "till":"", "to":"", "together":"", "too":"", "took":"", "toward":"", "towards":"", "tried":"", "tries":"", "true":"", "truly":"", "try":"", "trying":"", "t''s":"", "twice":"", "two":"", "un":"", "under":"", "underneath":"", "undoing":"", "unfortunately":"", "unless":"", "unlike":"", "unlikely":"", "until":"", "unto":"", "up":"", "upon":"", "upwards":"", "us":"", "use":"", "used":"", "useful":"", "uses":"", "using":"", "usually":"", "utterly":"", "value":"", "various":"", "versus":"", "very":"", "via":"", "viz":"", "vs":"", "want":"", "wants":"", "was":"", "wasn''t":"", "way":"", "we":"", "we''d":"", "welcome":"", "well":"", "we''ll":"", "went":"", "were":"", "we''re":"", "weren''t":"", "we''ve":"", "what":"", "whatever":"", "what''ll":"", "what''s":"", "what''ve":"", "when":"", "whence":"", "whenever":"", "where":"", "whereafter":"", "whereas":"", "whereby":"", "wherein":"", "where''s":"", "whereupon":"", "wherever":"", "whether":"", "which":"", "whichever":"", "while":"", "whilst":"", "whither":"", "who":"", "who''d":"", "whoever":"", "whole":"", "wholly":"", "who''ll":"", "whom":"", "whomever":"", "who''s":"", "whose":"", "why":"", "will":"", "willing":"", "wish":"", "with":"", "within":"", "without":"", "wonder":"", "wondered":"", "wondering":"", "won''t":"", "worst":"", "would":"", "wouldn''t":"", "yes":"", "yet":"", "you":"", "you''d":"", "you''ll":"", "your":"", "you''re":"", "yours":"", "yourself":"", "yourselves":"", "you''ve":"", "zero":"" }' >
<cfset var wordsToAvoid = DeSerializeJSON(wordsToAvoidJSON) />
<cfset var pc = "" />
<cfhttp url="#trim(page)#" method="get"></cfhttp>
<cfset pc = LCase(cfhttp.fileContent) />
<cfset pc = Replace(pc,">",">","All") />
<cfset pc = Replace(pc,"<","<","All") />
<cfset pc = Replace(pc," "," ","All") />
<cfset pc = REReplaceNoCase(pc,"<head[^>]*?>.*?</head>"," ","ALL")>
<cfset pc = REReplaceNoCase(pc,"<style[^>]*?>.*?</style>"," ","ALL")>
<cfset pc = REReplaceNoCase(pc,"<script[^>]*?.*?</script>"," ","ALL")>
<cfset pc = REReplaceNoCase(pc,"<object[^>]*?.*?</object>"," ","ALL")>
<cfset pc = REReplaceNoCase(pc,"<embed[^>]*?.*?</embed>"," ","ALL")>
<cfset pc = REReplaceNoCase(pc,"<applet[^>]*?.*?</applet>"," ","ALL")>
<cfset pc = REReplaceNoCase(pc,"<noframes[^>]*?.*?</noframes>"," ","ALL")>
<cfset pc = REReplaceNoCase(pc,"<noscript[^>]*?.*?</noscript>"," ","ALL")>
<cfset pc = REReplaceNoCase(pc,"<noembed[^>]*?.*?</noembed>"," ","ALL")>
<cfset pc = REReplaceNoCase(pc,"<(.*?)>"," ","ALL")>
<cfset pc = REReplaceNoCase(pc,"[^a-zA-Z0-9.']"," ","ALL")>
<cfset pc = REReplaceNoCase(pc,"\s+"," ","ALL")>
<cfset pc = Replace(pc,"."," ","ALL")>
<cfset pcArray = pc.split(" ") />
<cfloop from="1" to="#ArrayLen(pcArray)#" index="i">
<cfset tempWord = trim(pcArray[i]) />
<cfif len(tempWord) GT 1 AND NOT IsNumeric(tempWord)>
<cfif NOT StructKeyExists(wordsToAvoid, tempWord)>
<cfif StructKeyExists(wordsCountStruct, tempWord)>
<cfset wordsCountStruct[tempWord] = wordsCountStruct[tempWord] + 1 />
<cfelse>
<cfset StructInsert(wordsCountStruct, tempWord, 1) />
</cfif>
</cfif>
</cfif>
</cfloop>
<cfreturn wordsCountStruct />
</cffunction>
Ginger CMS
the future of cms, a simple and intuitive content management system ... ASP.NET MVC Application
best practices like Repository, LINQ, Dapper, Domain objects ... CFTurbine
cf prototyping engine, generates boilerplate code and views ... Search Engine LITE
create your own custom search engine for your web site ... JRun monitor
monitors the memory footprint of JRun engine and auto-restarts a hung engine ... Validation Library
complete validation library for your web forms ...
the future of cms, a simple and intuitive content management system ... ASP.NET MVC Application
best practices like Repository, LINQ, Dapper, Domain objects ... CFTurbine
cf prototyping engine, generates boilerplate code and views ... Search Engine LITE
create your own custom search engine for your web site ... JRun monitor
monitors the memory footprint of JRun engine and auto-restarts a hung engine ... Validation Library
complete validation library for your web forms ...